
Block Tasks Dataset
The dataset contains the multi-view rgb data.
Oier Mees, Markus Merklinger, Gabriel Kalweit, Wolfram Burgard
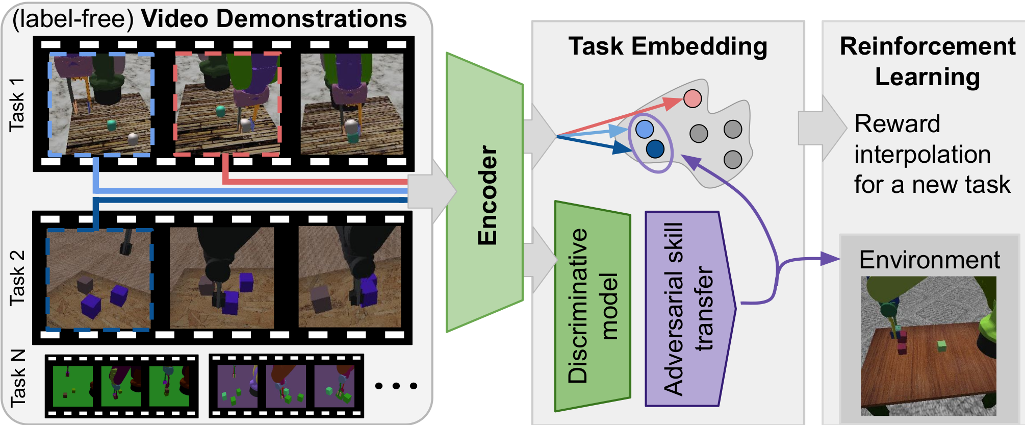
Given the demonstration of a new task as input, our approach called Adversarial Skill Networks (ASN) yield a distance measure in skill-embedding space which can be used as the reward signal for a reinforcement learning agent for novel tasks that require a composition of previously seen skills.

Intelligent beings have the ability to discover, learn and transfer skills without supervision. Moreover, they can combine previously learned skills to solve new tasks. This stands in contrast to most current "deep reinforcement learning" (RL) methods, which, despite recent progress, typically learn solutions from scratch for every task and often rely on manual, per-task engineering of reward functions. Furthermore, the obtained policies and representations tend to be task-specific and generally do not transfer well to new tasks.
The design of reward functions that elicit the desired agent behavior is especially challenging for real-world tasks, particularly when the state of the environment might not be accessible. Additionally, designing a reward function often requires the installation of specific sensors to measure as to whether the task has been executed successfully. In many scenarios, the need for manual, task-specific engineering of reward functions prevents us from end-to-end learning from pixels, if the reward function itself requires a dedicated perception pipeline. To address these problems, we propose an unsupervised skill learning method that aims to discover and learn transferable skills by watching videos, without supervision, and that is useful for guiding an RL-agent to solving a wide range of tasks by composing previously seen skills. To learn more, see the Technical Approach section.
Adversarial Skill Networks: Unsupervised Robot Skill Learning from Video
Key challenges for the deployment of reinforcement learning (RL) agents in the real world are the discovery, representation and reuse of skills in the absence of a reward function. To this end, we propose a novel approach to learn a task-agnostic skill embedding space from unlabeled multi-view videos. Our method learns a general skill embedding independently from the task context by using an adversarial loss. We combine a metric learning loss, which utilizes temporal video coherence to learn a state representation, with an entropy regularized adversarial skill-transfer loss. The metric learning loss learns a disentangled representation by attracting simultaneous viewpoints of the same observations and repelling visually similar frames from temporal neighbors. The adversarial skill-transfer loss enhances re-usability of learned skill embeddings over multiple task domains. We show that the learned embedding enables training of continuous control policies to solve novel tasks that require the interpolation of previously seen skills. The approach is being developed by members from the Autonomous Intelligent Systems group at the University of Freiburg, Germany.
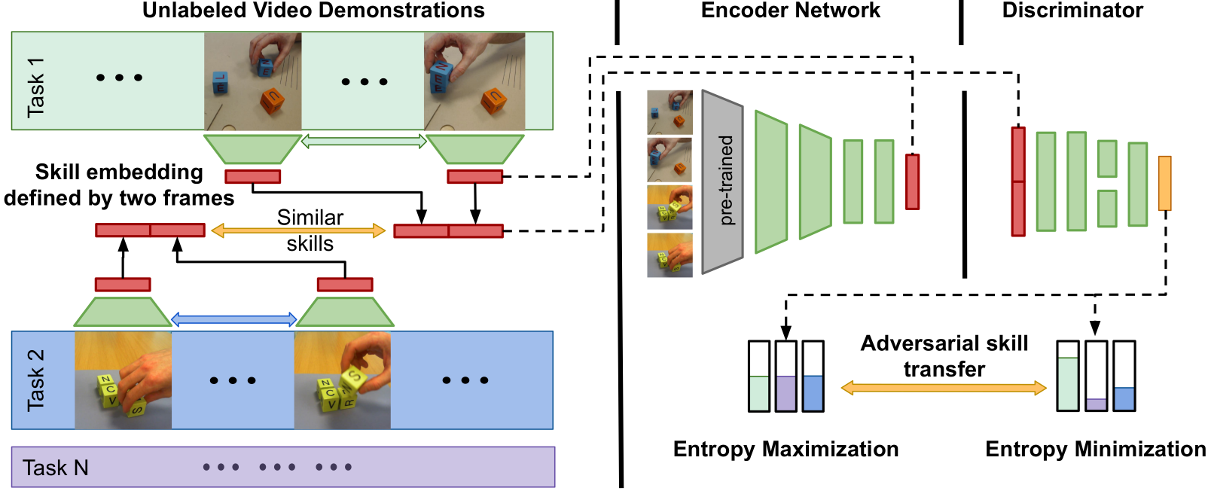
We represent the skill embedding as a latent variable and apply an adversarial entropy regularization technique to ensure that the learned skills are task independent and versatile and that the embedding space is well formed. Training an RL-agent to re-use skills in an unseen tasks, by using the learned embedding space as a reward function, solely requires a single video demonstrating the novel task. This makes our method readily applicable in a variety of robotics scenarios.


We evaluate the performance of ASN on two data sets. The first data set consisted of three simulated robot tasks: stacking (A), color pushing (B) and color stacking (C). The data set contains 300 multi-view demonstration videos per task. The tasks are simulated with PyBullet. Of these 300 demonstrations, 150 represent unsuccessful executions of the different tasks. We found it helpful to add unsuccessful demonstrations in the training of the embedding to enable training RL agents on it. Without fake examples, the distances in the embedding space for states not seen during training might be noisy. The test set contains the manipulation of blocks. Within the validation set, the blocks are replaced by cylinders of different colors.



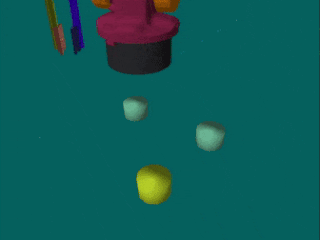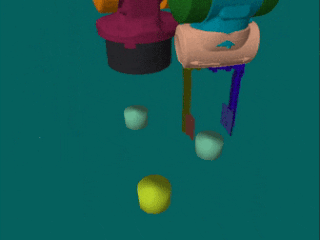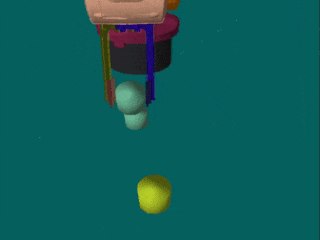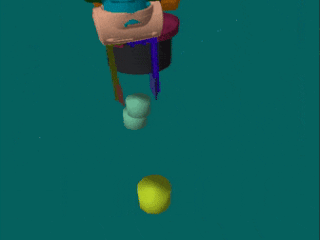
The second data set includes real-world human executions of the simulated robot tasks (A, B and C), as well as demonstrations for a task where one has to first separate blocks in order to stack them (D). For each task, we have 60 multi-view demonstration videos, corresponding to 24 minutes of interaction. In contrast to the simulated data set, the real demonstrations contain no unsuccessful executions and are of varying length. The test set contains blocks of unseen sizes and textures, as well as unknown backgrounds.
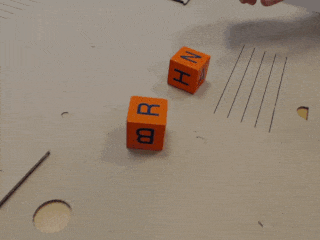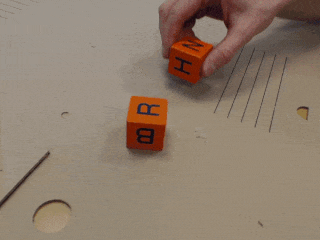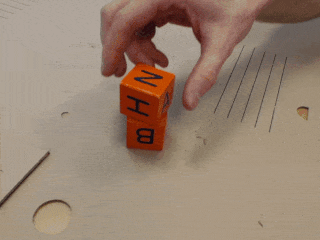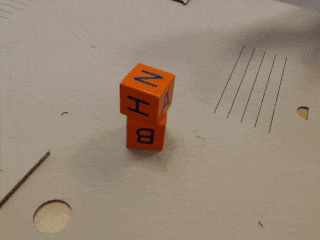


Please cite our work if you use the block task dataset or report results based on it.
@INPROCEEDINGS{mees20icra_asn,
author = {Oier Mees and Markus Merklinger and Gabriel Kalweit and Wolfram Burgard},
title = {Adversarial Skill Networks: Unsupervised Robot Skill Learning from Videos},
booktitle = {Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)},
year = 2020,
address = {Paris, France}
}This dataset is is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License and provided for research purposes only. Any commercial use is prohibited. If you use the dataset in an academic context, please consider citing our paper.



